<< Learning Center
Media Accessibility Information, Guidelines and Research
DCMP's AI Scene Description Tool
DCMP operates the nation’s largest fully-accessible educational video platform, with a library of 18,000 videos designed for use by early learner through Grade 12 students with disabilities. Our development team has been working on ways to use artificial intelligence (AI) to help with accessibility challenges, including those that might be considered “impossible.” We’re excited to present “AI Scene Description,” a new tool for students who are blind and have low vision that can describe the visual elements of any frame within a paused video.
There may be times when you and your students need a little more information about the contents of a scene, but there's not enough quiet time in the video to describe everything. With DCMP's AI Scene Description tool, you can now have any selected scene described.
DCMP developed a method of generating scene descriptions that relies strongly on human-created metadata for each video. This additional context guides the AI in creating more accurate scene descriptions that are grade appropriate.
DCMP's AI Scene Description tool is a supplement, not a replacement, for audio description. DCMP will continue to produce audio description with talented writers and voicers.
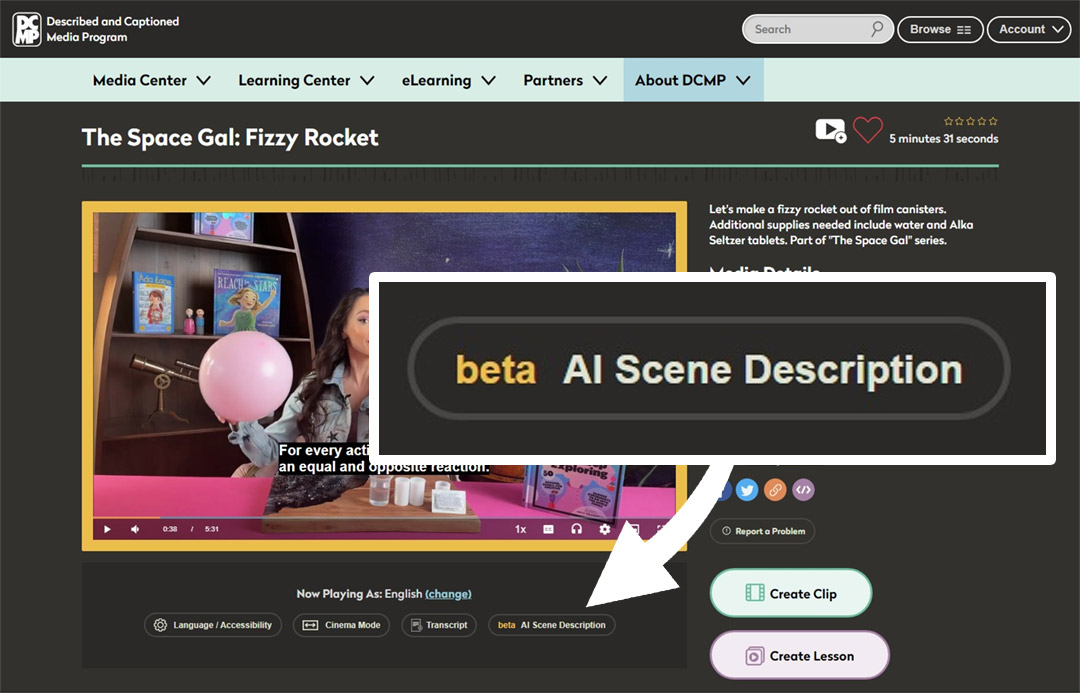
The AI Scene Description beta tool is now live and integrated into DCMP’s video player. It is limited to registered members. Direct use with students is by opt-in only – DCMP members must grant permission to students through Student Accounts. Teachers will find this option by going to Account > Students, and selecting “Allow students to use AI Scene Description.”
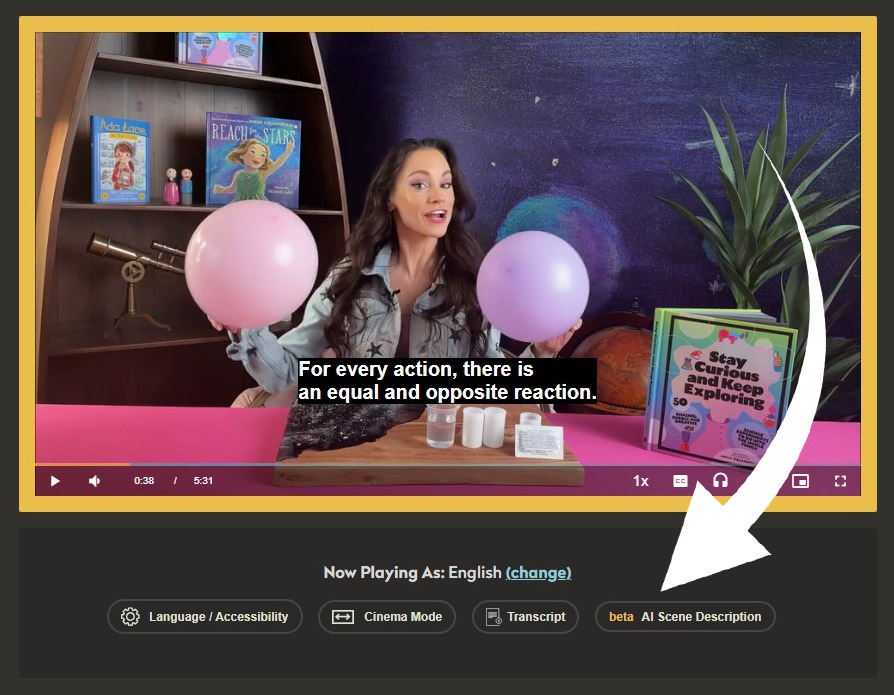
So how does the AI Scene Description tool work? Log in to dcmp.org and select the “beta AI Scene Description” button under any video. In this example from an episode of The Space Gal, we’ve paused the video at a scene where Emily Calandrelli is in her studio holding two balloons. We then select the AI Scene Description button, and a description of the scene is spoken via text-to-speech and transcribed.
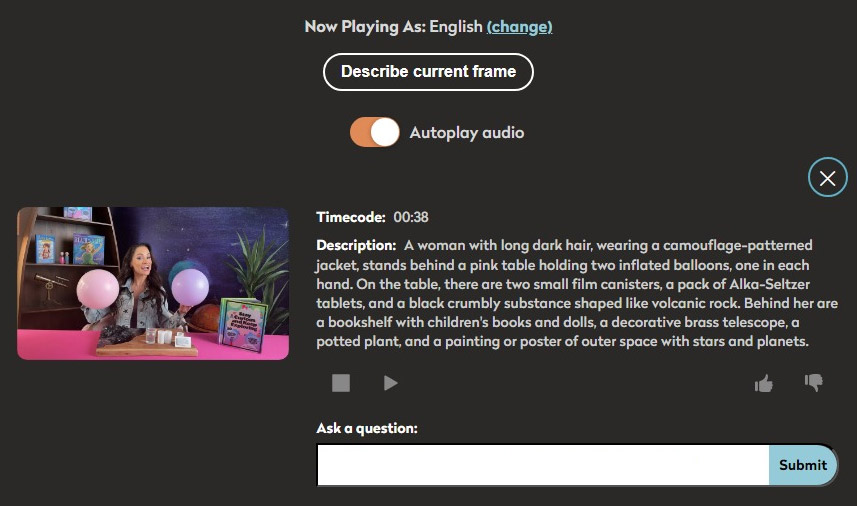
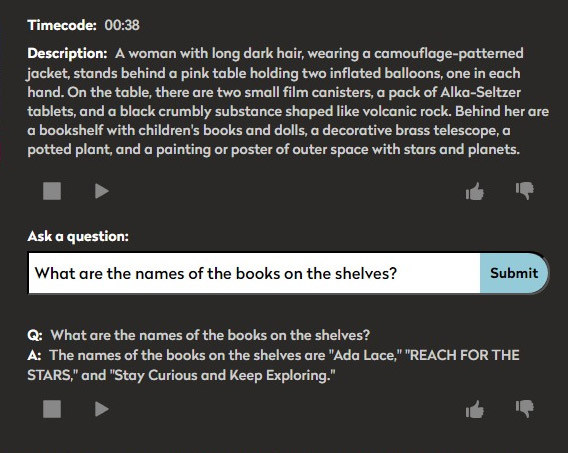
The feature also allows for users to ask more detailed questions about the scene. We’ve added guardrails to keep the AI responses contextual to the video; for example, there is no “memory” between multiple questions, so users cannot have a “conversation” with the AI tool.
Once you’ve heard the description of the scene, you can ask more detailed questions about the scene. For example, in this scene, you might ask, “What books are on the shelves?” Descriptions and answers will always use vocabulary based on the video’s grade level, and will take into account things like the applied educational standards, captions, and audio description.
We never submit any user data to any AI model or external service. We take user privacy seriously and have ongoing privacy agreements with states and districts across the country. We also seek user feedback through the “Provide Beta Feedback” button on each video’s web page.
Tags:
Please take a moment to rate this Learning Center resource by answering three short questions.
